|
|
| Niveau | Débutant |
| Logiciels utilisés |
|
| Plateforme | Windows | Mac | Linux | FreeBSD |
L'examen des questions et des réponses sur le ForumSig montre que la plupart des Sigistes ignorent ou même n'ont jamais entendu parler des expressions régulières.
C'est pourtant une des méthodes les plus puissantes pour effectuer des recherches dans les documents (textes, fichiers, champs d'une base de données, etc.)
Pourquoi ai-je été amené à les apprendre ?
- au départ, comme tout le monde, je suppose, une expression comme ([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6}) me paraissait une langue totalement ésotérique et dont je ne voyais pas l'utilité pratique.
- confronté à des problèmes de recherche / remplacement non réalisables par les démarches classiques sur plus de 50000 fichiers, ou devoir extraire des coordonnées xy sur des énormes fichiers où les coordonnées n'étaient pas encodées de la même manière, j'ai commencé à m'intéresser à ces expressions, sinon, c'était recréer les 50000 fichiers...
- j'ai donc commencé à les pratiquer avec beaucoup de désillusions au départ (« pourquoi cette *?!!+- ne marche pas, nom d'une pipe... !» .
- peu à peu, un déclic s'est produit et tout d'un coup c'est devenu plus facile pour mes cas particuliers.
Je pense maintenant que la démarche en valait vraiment la peine, car il est possible d'isoler ce que je veux, de le traiter et / ou de le remplacer dans n'importe quel document ou fichier.

Regular Expression de xkcd.com/208/
Les tutoriels sont innombrables sur Internet et je ne vais pas vous en proposer un autre, mais plutôt essayer de vous en expliquer les principes et surtout vous donner envie de les utiliser. Après une présentation rapide, nous verrons comment construire une expression régulière et l'utiliser avec deux petits exemples pratiques.
C'est quoi, une expression régulière ?
Lorqu'on utilise la chaîne «*.shp » pour rechercher des fichiers de type shapefile, ce qu'on demande en fait est :
« n'importe quel nom de fichier se terminant par .shp ».
Ce motif de recherche contient * qui signifie
« chaîne avec n'importe quel nombre et type de caractères » (hormis exceptions suivant les OS).
C'est ce qu'on appelle un métacaractère (fr.wikipedia.org/wiki/M%C3%A9tacaract%C3%A8re).
Les expressions régulières fonctionnent de cette manière, mais avec des motifs de recherche composés à l'aide de caractères et de métacaractères, plus nombreux et plus puissants.
Au niveau vocabulaire, le terme anglais est « regular expression » (souvent abrégé en regexp voire regex), qui a donné en français une traduction correcte « expression rationnelle » (comme dans Wikipedia) et une traduction littérale « expression régulière ». La seconde est entrée dans les moeurs.
Tous les langages de programmation permettent l'utilisation des expressions régulières, les éditeurs de textes courants comme Notepad++, Pspad, ou UltraEdit sur Windows, tous les éditeurs de texte sur les systèmes Unix comme Mac OS X ou Linux, les commandes sed ou grep, les bases de données comme PostgreSQL, MySQL, Oracle ou SQL server, Open Office ou Microsoft avec Word, Excel ou Access (les sites de Microsoft offrent de nombreux tutoriels et explications) ainsi que les SIGs ArcGIS, Quantum GIS, etc.
Les sites Web utilisent aussi abondamment ces expressions pour contrôler le format de ce qui leur est soumis (adresses e-mail, code postaux, numéros de cartes de paiement avec par exemple, des expressions utilisées pour vérifier si un numéro de carte Visa est valide comme ^4[0-9]{12}(?:[0-9]{3})?$, ^([4]{1})([0-9]{12,15})$ ou ...)
Principes « express »
Les expressions régulières vont donc permettre de rechercher une chaîne de caractères dans un texte littéralement ou à l'aide d'un motif de recherche (pattern en anglais, patron) construit avec des caractères et des métacaractères.
Précisons tout de suite que ce n'est pas un langage, ce sont des expressions qui permettent de rechercher et / ou de traiter (extraire, ajouter, remplacer, supprimer) des chaines de caractères. Pour les utiliser, il faut utiliser un langage ou une application. Suivant ceux-ci, les implémentations peuvent varier (même si le standard POSIX offre un standard, certains langages comme PERL offrent plus de fonctionnalités, par exemple), mais la base est la même.
Ce qu'il faut bien comprendre, c'est qu'il y a un changement de paradigme, on ne recherche pas des mots ou des phrases comme dans les démarches classiques, mais uniquement des chaînes de caractères (ou un motif c'est-à-dire la manière dont l'élément recherché est formaté, comme l'exemple avec les cartes Visa).
Il y a de nombreux testeurs d'expression régulière en ligne comme gskinner.com/RegExr/, regexpal.com/, etc. des extensions pour Firefox comme addons.mozilla.org/en-US/firefox/addon/regular-expressions-tester/) et des programmes. Je vous conseille vivement d'en utiliser un pour débuter.
extension Firefox
Construction des expressions
Soit l'extrait de texte suivant :

Nous allons examiner comment construire des expressions régulières permettant de sélectionner exactement ce que l'on veut (ce texte peut être brut, un champs d'une base de données, etc.) à l'aide de métacaractères réservés qui vont servir à construire des motifs de recherche. Ceux-ci sont (ils seront examinés dans la suite):
![]()
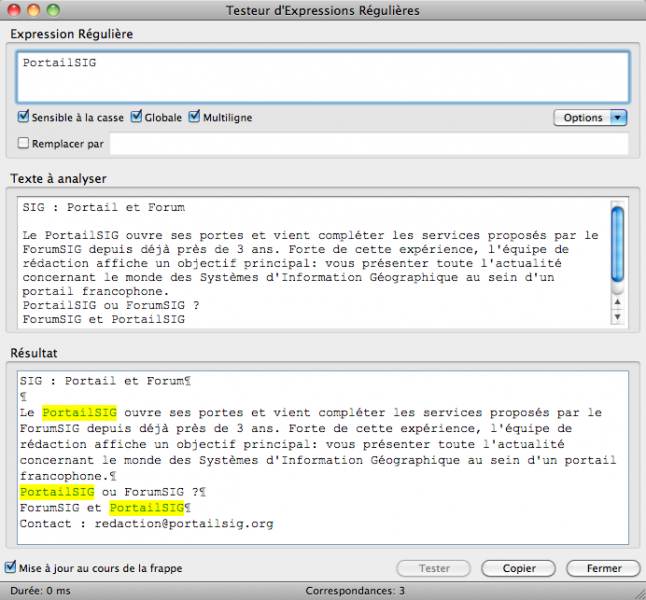
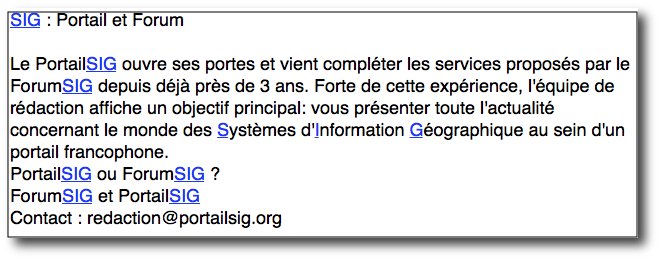
- Le motif le plus simple est la chaîne littérale. Tous les caractères, sauf les caractères réservés, ne représentent qu'eux-mêmes. Ils sont aussi sensibles à la casse. Ainsi, SIG recherche littéralement la chaine « SIG » (S suivi de I suivi de G), et non sig. Il y a moyen de rechercher une occurrence ou toutes les occurrences (ce qui est le cas dans la suite de la présentation).
recherche de SIG

- Le « joker » est le . qui signifie n'importe quel caractère (et non le * comme dans la recherche de fichiers) :
Recherche de o.t

- Comme c'est un caractère réservé, se pose alors le problème de savoir comment rechercher le vrai point. La solution est d'utiliser le caractère barre oblique inversée (backslach). \. recherchera tous les points (\? tous les points d'interrogation, \\ pour le backslash etc.) :
recherche des points \.

- De même, pour rechercher les caractères non visibles, comme les fins de ligne ou les tabulations, il existe des métacaractères comme \n pour la fin de ligne \r pour le retour charriot ou \t pour la tabulation (dépend de l'encodage sur chaque OS).
recherche des fins de ligne (\n)
- Il est possible d'ancrer les chaînes ou les classes, c'est à dire de savoir si le motif de recherche est au début d'une chaîne ^SIG ou à la fin SIG$ (attention une chaîne va du début jusqu'à la fin d'une ligne terminée par \n !) :
recherche de ^SIG recherche de SIG$


- de la même manière, il est aussi possible d'ancrer un « mot », c'est-à-dire une chaîne de caractères encadrée par des espaces ou autres, avec \b (attention, ce n'est pas la recherche littérale du mot, mais de caractères encadrés par quelque chose), comme \bet\b (= espace(s) et espace(s)) :

- Ces mêmes caractères, entre crochets, vont exprimer une liste de choix. Ainsi la recherche de [SIG] fournira toutes les occurrences des 3 caractères S ou I ou G (en majuscule) :
Recherche de [SIG]
- C'est ce qu'on appelle les classes de caractères. Pour éviter des listes trop longues, un tiret est utilisé. Ainsi, l'expression [A-Z] va rechercher toutes les majuscules, [ ], les espaces ou [0-9], tous les chiffres, par exemple. [Portail]SIG trouvera PSIG, oSIG, lSIG mais pas bSIG. Ces listes sont aussi cumulables : [0-27-9] va rechercher tous les caractères numériques, sauf 3,4,5, et 6 :
recherche de [A-Z] recherche de [0-9]

- Si on veut exclure de la recherche certains caractères (négation), il existe des assertions : [^Dd] signifie ni D ni d, [^a-z] signifie rechercher les caractères qui ne sont pas dans l'intervalle a - z (minuscules) :
recherche de [^a-z]
- On remarque tout de suite que le résultat n'est pas égal à celui de [A-Z], il y a en plus les fins de ligne, les espaces ou les ponctuations, mais aussi les lettres accentuées. Pour sélectionner les lettres accentuées, il faut les spécifier [éèàùâêîôûäëïöü] (voir aussi \w dans la suite avec les caractères Unicode) :
recherche de [éèàùâêîôûäëïöü]

- mais les éléments les plus importants et peut-être les plus difficiles à appréhender sont les quantificateurs. Ils fournissent la possibilité de préciser le nombre d'occurrences d'un caractère, d'un métacaractère ou d'un motif de recherche (plusieurs a de suite, par exemple).
- Les principaux quantificateurs sont
- ? ce symbole indique que le motif est facultatif. Il peut apparaître 0 ou 1 fois ;
- + ce symbole indique que le motif est obligatoire. Il peut apparaître 1 ou plusieurs fois;
- * ce symbole indique que le motif est aussi facultatif, mais à la différence de ?, il peut apparaître 0 ou plusieurs fois.
- on voit tout de suite qu'il y a des correspondances comme a+ = aa* (au moins une occurrence de a)
recherche de abc* (c facultatif) recherche de abc+ (c obligatoire)
![]()
![]()
- Pour regrouper et / ou mémoriser un ensemble de plusieurs lettres dans un motif, il suffit de les placer entre parenthèses, (abc)+ (c'est un groupe, qui peut être capturant ou non, mais ce concept dépasse le cadre de cet article) :
recherche de (abc)+ (au moins un abc obligatoire)
![]()
- L'alternative entre des éléments de plusieurs caractères est exprimée par | (pipe en anglais), et s'applique aux groupes : (Portail|Forum) recherchera Portail ou Forum :

- Il est aussi possible de spécifier une plage d'occurrence :
- [0-9]{4} désigne toute suite de 4 chiffres;
- [0-9]{4,} recherche une suite d'au moins 4 chiffres;
- [0-9]{3,5} recherche toute suite entre 3 et 5 chiffres;
- a{5} recherche exactement 5 a se suivant;
- abc{2} trouvera abcc mais pas abcabc alors que (abc){2}, oui
- il est possible de voir les correspondances entre les notations :
- ? = {0,1},
- + = {1,}
- * = {0,}
recherche de code postal français (5 chiffres se suivant) : [0-9]{5}
![]()
- La plupart des implémentations autorisent des raccourcis :
- \w : équivaut à [0-9a-zA-Z]
- \W : équivaut à [^0-9a-zA-Z]
- \d : équivaut à [0-9]
- \D : équivaut à [^0-9]
- \s : équivaut à espace, tabulation, saut de ligne, ou tout autre caractère non imprimable
- \S : l'inverse de \s
- Il est aussi possible d'appliquer tous les éléments que nous venons de voir comme \d{5} = \d\d\d\d\d.
- ces raccourcis peuvent permettre la recherche des lettres accentuées en utilisant la norme Unicode
recherche de \w + sans Unicode recherche de \w + avec Unicode

- et enfin tous ces métacaractères peuvent parfaitement être combinés pour résoudre les problèmes (et mémorisés pour les recherches, les backreferences, mais c'est une autre histoire que nous n'aborderons pas ici) comme :
(Portail|Forum)[a-zA-Z]+ ou (Portail|Forum)\w+

- ou (((motif1)[ ](motif2))motif3) , etc., mais ça devient vite difficile à décrypter...
En pratique
exemple de construction d'une expression :
Il y a plusieurs manières de construire une expression régulière pour arriver au résultat désiré. Il suffit d'examiner les questions / réponses fournies sur le site stackoverflow.com/questions/tagged/regex pour s'en convaincre...
exemples de plusieurs expressions donnant le même résultat pour sélectionner la phrase suivante:
![]()
- Le[ ]*[a-z]+[ ]*.*;
- [A-Za-z]+[ ]*[a-z]+[ ]*.*;
- [\w]+[ ]+[\w]+[ ]*.*;
- [\w]+\s+[\w]+\s*.*;
- ^Le[ ]+([a-z]+)[ ]*.*;
- Le\s(\w+)\s.*?;
- Le\s([a-z]+)\s.*;
- etc.
Certains considèrent cette construction comme un art. Ils vont chercher à obtenir la « meilleure » solution (c'est-à-dire celle qui est valable dans tous les cas de figure) et vont souvent critiquer les « mauvaises » solutions...
Mais, en pratique, comment se construit une expression ?
Nous allons illustrer ici, simplement, une démarche pour chercher « redaction@portailsig.org » dans le texte soumis (cas particulier), et ce, non littéralement, afin que l'expression puisse être utilisée pour rechercher toutes les adresses e-mail dans le même contexte.
1) Le premier élément qu'il est possible de chercher est le caractère arobase @ (en recherche littérale) :

2) puisque l'arobase est entourée de caractères, on pourrait utiliser le joker .+@.+\..+ qui signifie en décomposant :
- .+ -> au moins un caractère ou plus,
- @ -> littéral,
- .+ -> au moins un caractère ou plus,
- \. -> point
- .+ au moins un caractère ou plus.
![]()
3) le résultat n'est pas satisfaisant puisque « Contact : » est aussi trouvé. Le mot redaction comportant 9 lettres, on pourrait utiliser [a-z]{9}@.+\..+ ou plus généralement [a-z]+@.+\..+ puisqu' il peut y avoir plus ou moins de lettres (ou \w+@.+\..+ ou ...). En décomposant
- [a-z]+ ou w+ -> au moins une lettre ou plus, ([a-z]{9} -> exactement 9 lettres),
- @ -> littéral,
- .+ -> au moins un caractère ou plus,
- \. -> point,
- .+ -> au moins un caractère ou plus.
![]()
4) ce qui nous donne une solution mais il suffit d'avoir comme adresse, martin.laloux@portailsig.org, et l'expression ne marche plus. La partie droite d'une adresse e-mail étant généralement constituée d'une suite de caractères suivie d'un point suivie d'une suite de caractère on essaie l'expression [a-z]+\.?[a-z]+@.+\..+ (ou \w+\.?\w+@.+\..+ avec ? (facultatif) et non + (obligatoire) sinon ça ne marcherait plus avec redaction@portail.sig). En décomposant :
- [a-z]+ ou w+ -> au moins une lettre ou plus,
- \.? -> 0 ou 1 point
- [a-z]+ ou w+ -> au moins une lettre ou plus,
- @ -> littéral,
- .+ -> au moins un caractère,
- \. -> point,
- . + -> au moins un caractère ou plus.
![]()
5) Encore une fois l'expression ne marcherait pas si l'adresse se terminait par portail.sig.fr, par exemple, mais, sans être des artistes, vous avez tous les éléments pour résoudre le problème. La solution donnée ici n'est valable que pour ce cas très particulier.
Ce problème de la validité d'une adresse e-mail est en effet crucial sur Internet où il faut vérifier, par exemple, si une adresse soumise est correcte ou non (format). Ceci implique que tous les cas particuliers doivent être vérifiés pour obtenir, in fine, l'expression la plus générale possible. Il est possible de vérifier sur le site fightingforalostcause.net/misc/2006/compare-email-regex.php les «meilleures » expressions pour résoudre ce problème. En JavaScript, selon eux, la meilleure est :
/^[-a-z0-9~!$%^&*_=+}{\'?]+(\.[-a-z0-9~!$%^&*_=+}{\'?]+)*@([a-z0-9_][-a-z0-9_]*(\.[-a-z0-9_]+)*\.(aero|arpa|biz|com|coop|edu|gov|info|int|mil|museum|name|net|org|pro|travel|mobi|[a-z][a-z])|([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(:[0-9]{1,5})?$/i
Je suis loin du compte avec ma petite solution, mais elle marche dans ce cas particulier et c'est ce qui compte.
Cette démarche illustre un des problèmes rencontrés avec les expressions régulières. Il est nécessaire d'envisager toutes les solutions au regard de tous les cas particuliers pour aboutir à une solution générale ce qui implique de bien connaître la structure du document traité. Ainsi, l'expression [0-9]{5} utilisée pour chercher les codes postaux français dans un texte n'est valide que s'il n'y a aucune suite de 5 chiffres qui ne soit pas un code postal. Sinon, il faut chercher une autre solution qui permet de les isoler.
autre exemple pratique :
Et pour terminer, illustrons un problème auquel j'ai déjà été souvent confronté. Examinons un extrait du fichier délimité suivant :

On remarque tout de suite qu'il y a beaucoup d'erreurs (exagérées ici). Il y deux solutions, soit je demande de refaire le fichier, soit je trouve une méthode de traitement. Supposons que je veuille sélectionner les coordonnées y ( y = suivi des valeurs numériques) ou uniquement les valeurs numériques x et y (que ce soit avec point ou virgule comme délimiteur pour les décimales) pour les traiter ensuite.
Impossible, me dites-vous ? Que nenni !
1) valeurs y = **** -> y[ ]*=[ ]*\d+[\.|,]?\d+ ou y\s*=\s*\d+[\.|,]?\d+, c'est à dire :
- y -> littéral,
- [ ]* -> 0 à n espaces (ou \s*),
- = -> littéral,
- [ ]* - > 0 à n espaces (ou \s*),
- \d+ -> 1 à n chiffres,
- [\.|,]? -> point ou virgule (0 ou 1 fois),
- \d+ -> 1 à n chiffres.
- 123 seul est capturé par y[ ]*=[ ]*\d+ (il n'y a plus rien après 123, ni point, ni virgule, ni chiffre, mais un espace non signalé dans l'expression)
- le reste est capturé par [\.|,]? \d+.

- de la même manière, s'il y avait un espace après la virgule, comme 154, 42, il suffit d'adapter l'expression, y\s*=\s*\d+[\.|,]?\s*\d+
- ainsi l'expression se complète peu à peu pour arriver à une solution générale qui marche dans tous les cas de figure.
- on peut arriver à une abstraction quasi totale, c'est à dire, presque sans aucun caractère littéral y\s*\W\s*\d+[\.|,]?\s*\d+ ou y\s*.\s*\d+[\.|,]?\s*\d+ (si le y est remplacé par \w, on aura aussi les valeurs x =). En décomposant :
- y -> littéral,
- \s* -> 0 à n espaces,
- \W ou . -> un caractère non lettre ou un caractère,
- \s* - > 0 à n espaces,
- \d+ -> 1 à n chiffres,
- [\.|,]? -> point ou virgule (0 ou 1 fois),
- \s* -> 0 à n espaces,
- \d+ -> 1 à n chiffres.
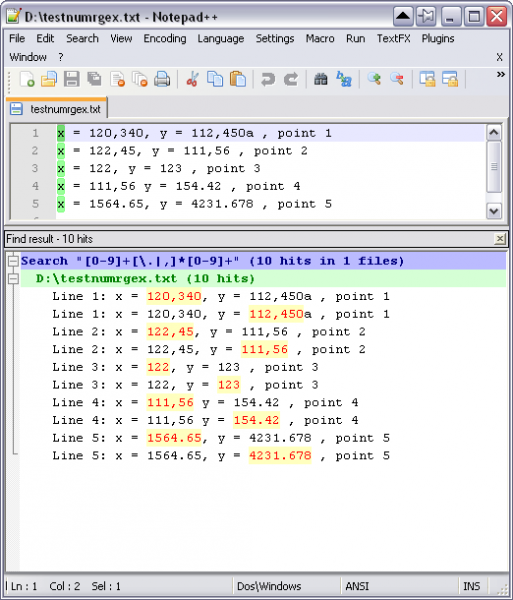
2) pour extraire les valeurs numériques xy seules -> [0-9]+[\.|,]*[0-9]+ ou \d+[\.|,]*\d+
- [0-9]+ -> 1 à n chiffres (ou \d+),
- [\.|,]* -> point ou virgule (0 ou 1 fois),
- [0-9]+ -> 1 à n chiffres (ou \d+).

3) L'ensemble sélectionné peut ensuite être traité pour normaliser les coordonnées avec un langage ou un logiciel adéquat (pour nettoyer, éliminer et / ou remplacer).
- Comme j'utilise beaucoup Python, un exemple de traitement (voir aussi www.portailsig.org/content/comment-recuperer-les-chiffres-d-un-champ-texte) :
expressions régulières avec Python
- 5719 lectures
- ou avec Notepad++ (pour les utilisateurs de Windows) :
- ou en SQL ,
select * from mabase where monchamp ~ '[(abc(\s)?)+' -> PostgreSQL
select * from mabase where monchamp REGEXP '[(abc(\s)?)+' -> MySQL
select * from mabase where dbo.RegExMatch( monchamp,'[(abc(\s)?)+') -> SQL Server
- ce sont des requêtes tout à fait valides. Ainsi, une solution pour sélectionner tous les codes postaux français dans un champs avec PostgreSQL serait :
select regexp_matches(monchamp, '([0-9]{5})', 'g') as numstr from mabase
Conséquences
Et voilà, vous savez théoriquement résoudre quelques problèmes récemment posés sur le ForumSIG :
- [ArcGIS 9.x] Isoler les "n" derniers mot d'un champs (www.forumsig.org/showthread.php)
- [Access] Sélection de code postal dans un champ unique "adresse" (www.forumsig.org/showthread.php)
- [ArcGIS 9.x] Récupérer chiffres d'un champ texte (www.forumsig.org/showthread.php) ou www.portailsig.org/content/comment-recuperer-les-chiffres-d-un-champ-texte)
Conclusions
J'espère vous avoir donné une idée de ce qu'est une expression régulière, de comment la construire et de comment l'utiliser. Ne nous leurrons cependant pas, l'apprentissage n'est pas aussi facile, il faut les apprivoiser, « jouer » avec elles, mais le jeu en vaut la chandelle.
Et pour terminer ma démarche introduite dans l'introduction :
- je ne les utilise que dans mes cas particuliers et je ne cherche pas à être un « artiste », l'expression marche, c'est bon pour moi, même si elle peut paraître mal construite pour un spécialiste.
- j'utilise des testeurs d'expressions pour les construire avant de les appliquer.
- il y en a toujours qui me font râler car je n'arrive pas à comprendre pourquoi elles ne marchent pas ou pourquoi elles ne font pas ce que je voudrais qu'elles fassent...
- mais, je ne saurai plus m'en passer pour effectuer des recherches ou des recherches / remplacements.
Je ne fournis aucun lien ni aucune bibliographie, car il suffit de rechercher sur Internet. Il y a de tout, mais cela dépend de ce que l'on cherche (général, regex avec Notepad++, avec Python, PHP ou JavaScript, avec Microsoft Word, avec Oracle ou PostgreSQL, avec ArcGIS, etc.). De même, il y a de nombreux sites proposant des expressions prêtes à l'emploi (peu profitable si l'on n'essaye pas de les comprendre, de savoir exactement ce qu'elles font).
Tous les traitements ont été effectués sur Mac OS X avec grep ou RegHexhibit (un des nombreux testeurs d'expressions régulières pour Mac homepage.mac.com/roger_jolly/software/#regexhibit) et Inkscape pour les figures.
 Site officiel :
Expression rationnelle (Wikipedia)
Site officiel :
Expression rationnelle (Wikipedia) 
Commentaires
Actualité ? et Problèmes avec PGS
Bonjour,
Ces expressions régulières sont-elles encore très utilisées ou sont-elles remplacées par d'autres techniques ou d'autres langages ?
Pour info, j'ai l'impression que toutes ne marchent pas sous Postgresql. Ex : \bET\b
Merci,
Poster un nouveau commentaire