
![]()
Accéder avec Python aux bases de données, relationnelles ou non, est facilité par l'existence de la spécification Python Database API (DB API).
Cet API formalise les manières de se connecter à une base de données et d'effectuer tous les traitements: créations, requêtes, mises à jour ou suppression. Théoriquement, car cet API est plus ou moins bien respecté suivant les modules/bibliothèques.
Démarche classique: principes et exemples
Les principes de l'API sont relativement simples si l'on assimile bien la notion de "cursor" (en anglais, curseur, pointeur en français). Toute requête SQL est susceptible de fournir plus d'une ligne de résultats et plus d'un élément par ligne ou un tableau de valeurs. L'ensemble forme un curseur, qui est donc un objet informatique qui permet d'effectuer un traitement, d'en récupérer les résultats, généralement sous forme de tableaux ou de listes et de les traiter à l'aide de pointeurs.
Examinons maintenant la procédure en Python. Toutes les requêtes sont envoyées en SQL.
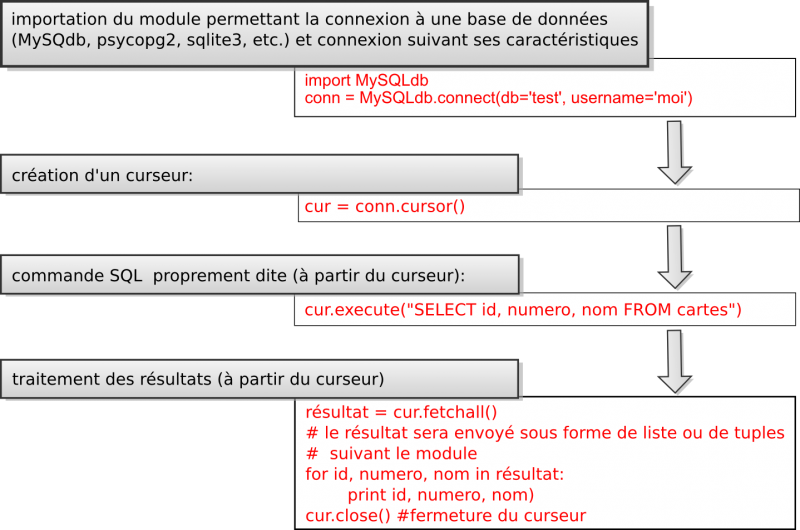
Appliquons ce principe pour effectuer des requêtes à deux bases de données spatiales, Postgis et SpatiaLite:
requête SELECT: Postgis
- 5756 lectures
Les résultats fournis par le curseur sont ici sous la forme d'une liste Python. Pour accéder aux divers éléments, il faudra donc utiliser des indices (pointeurs du curseur):
géométrie = poly[0]
srid = poly[1]
Insérer des données se fait de la même façon. Le processus sera appliqué à SpatiaLite, module spatial de SQLite (attention, il faut une version de SQLite qui accepte de charger des extensions, ce qui n'est pas le cas avec celle livrée avec Python > 2.5 pour le module sqlite3. La solution est donc de compiler une version de pysqlite2 à partir d'un SQLite adéquat. C'est facile avec Linux ou Mac OS X, pour Windows il faudra les télécharger sur le site de SpatiaLite (il y a aussi des applications complètes à télécharger: spatialite-gui et spatialite-gis).
requête INSERT: SpatiaLite
- 8255 lectures
Démarche classique: problèmes et solutions
Les procédures, bien que conformes à l'API, sont légèrement différentes. En pratique, des tables Postgis et SpatiaLite ne pourraient pas être traitées tout à fait de la même manière.
De plus pour accéder à chaque système de bases de données, il peut exister plusieurs modules (8 pour Postgresql, 2 pour Oracle...), chacun avec ses particularités propres et chacun respectant plus ou moins bien les règles de l'API.
Un autre problème est le manque d'unité du monde des bases de données. Bien qu'un standard SQL existe, les différences sont plus ou moins marquées entre les dialectes SQL, chacun y allant de ses ajouts ou de ses modifications pour se démarquer, avec les meilleurs arguments du monde.
La démarche classique se voit donc pénalisée:
- avant de commencer, il faut connaitre les caractéristiques du module de connexion choisi et les multiples avatars des dialectes SQL. Ainsi, le traitement de bases Oracle et MySQL peut être fort différent et le processus n'est pas portable;
- le principe du curseur est lourd et non "pythonesque". Il ne permet pas la pagination, c'est-à-dire qu'il ne permet pas l'accès à un élément particulier avant d'avoir obtenu tous les résultats en bloc. Cette technique n'est pas limitée au domaine des bases de données. Le module d'ESRI, argisscripting l'utilise et cela lui est souvent reproché (michalisavraam.org/2010/02/7-wishes-for-the-new-geoprocessor/ ou gissolved.blogspot.com/2009/04/using-for-loops-for-cursors.html );
- toute opération externe sur la base de données pourrait affecter tous les traitements SQL que les scripts pourraient réaliser.
La visibilité et le traitement des résultats peuvent être améliorés par l'utilisation de dictionnaires comme résultats:
exemple de curseur avec un dictionnaire comme résultat
- 6171 lectures
Dans le premier cas (the_geom), c'est le résultat brut au format binaire utilisé par Postgis (format WKB de l' OGC) qui est obtenu, dans le second, c'est un format texte qui est obtenu par la fonction AsText de Postgis (format WKT de l'OGC).
Tous les modules de connexion aux bases de données ne permettent cependant pas de faire ce genre de traitement. On peut alors utiliser la fonction toDict de code.activestate.com/recipes/528939-converting-dbi-results-to-a-list-of-dictionaries/, plus universelle:
traitement comparable avec la fonction toDict (universel)
- 6163 lectures
ou un peu plus compliqué comme, code.activestate.com/recipes/534114-list-wrapper-for-generators-indexable-subscriptabl/ qui permet d'accéder à n'importe quelle partie du résultat sans devoir en charger la totalité.
On le voit donc, l'idéal serait un procédé permettant d'accéder de la même manière à n'importe quelle base et de ne traiter que des objets Python, sans se préoccuper des particularités SQL ou autres. Des modules permettant de tels niveaux d'abstraction existent, depuis le simple parseur qui transforme les résultats d'un curseur (en dictionnaire comme l'exemple précédent), jusqu'à ceux qui libèrent le programmeur de toute commande SQL (wiki.python.org/moin/HigherLevelDatabaseProgramming). Parmi ces derniers, ceux qui utilisent le mapping objet-relationnel (ORM) sont les plus aboutis (modules SQLAlchemy, SQLObject ou GeoAlchemy, frameworks web comme Django, TurboGears, web2py ou MapFish).
Ce dernier thème est développé dans la suite :
"Python : les bases de données géospatiales - 2) mapping objet-relationnel (ORM, SQLAlchemy, SQLObject, GeoAlchemy, Django-GeoDjango, TurboGears ou MapFish)" www.portailsig.org/content/python-les-bases-de-donnees-geospatiales-2-mapping-objet-relationnel-orm-sqlalchemy-sqlobjec
Tous les traitements ont été effectués sur Mac OS X avec Python 2.5.4 et Inkscape pour la figure.
 Site officiel :
Python Database API
Site officiel :
Postgis
Site officiel :
SQLite
Site officiel :
SpatiaLite
Site officiel :
pysqlite2
Site officiel :
Python Database API
Site officiel :
Postgis
Site officiel :
SQLite
Site officiel :
SpatiaLite
Site officiel :
pysqlite2
Commentaires
Poster un nouveau commentaire