
|
|
| Niveau | Intermédiaire |
| Logiciels utilisés |
Python 2.7.x ou Python 3.x Pandas (module Python) GeoPandas (module Python) |
| Plateforme | Windows | Mac | Linux | FreeBSD |
Dans le monde géomatique, il y a ceux qui préfèrent les boutons, les menus, les pointer-cliquer, ou glisser-déplacer, le tout dans une jolie interface graphique (les SIGs quoi) et ceux qui préfèrent autre chose, comme la programmation directe et moi, malheureusement ou heureusement, je suis tombé dedans quand j’étais petit...
Parmi les nombreux modules Python existants, il y en a un qui me séduit de plus en plus, c’est GeoPandas (vu sommairement dans Python à finalité géospatiale: pourquoi débuter avec le module ogr alors qu’il existe des alternatives plus simples et plus didactiques ?) de Kelsey Jordahl, car il permet de pratiquement tout faire (attributs, géométries, jointures, etc.). Comme son nom l’indique, il est intrinsèquement lié à Pandas, mais force est de constater que la plupart des géomaticiens qui utilisent Python dans leurs logiciels SIG ne connaissent pas ce dernier module et pourtant...
Créé il y a relativement peu de temps, Pandas connaît un développement accéléré au point de devenir aujourd’hui l’un des principaux modules Python pour traiter les données de tout type ("Big Data", "Machine Learning", scientifique, économique, sociologique ...). Il s’appuie sur NumPy et permet de manipuler de grands volumes de données, structurées de manière simple et intuitive sous forme de tableaux.
Les exemples/tutoriels/videos sur Pandas sont innombrables sur Internet ainsi que des livres, aussi je me limiterai ici à une simple présentation de la structure des données pour passer ensuite à GeoPandas.
Pandas
![]()
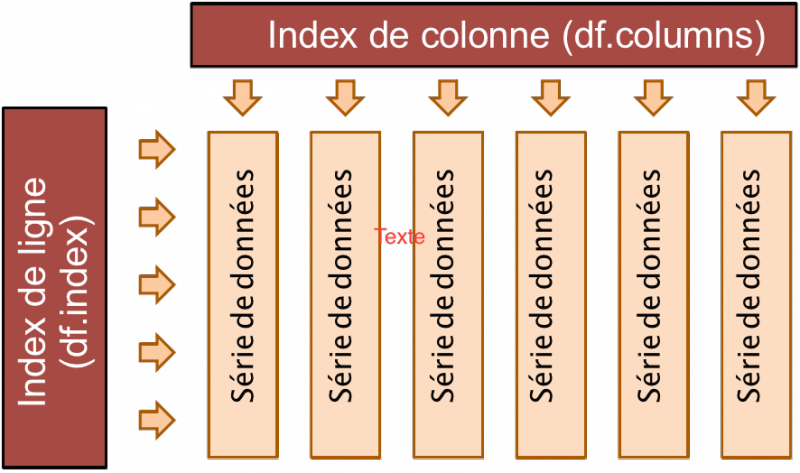
Figure modifiée de Cheat Sheet: The pandas DataFrame Object ( Dr. Stephen Sauchi Le)
Le type de base est la Serie (Pandas Series) qui peut être considérée comme un tableau de données à une dimension (grossièrement équivalent à une liste). L’extension en deux dimensions est un DataFrame (Pandas DataFrame). C’est un simple tableau dont les séries constituent les colonnes. Les index sont:
- index de colonne (df.columns()): les noms des colonnes (généralement des chaînes de caractères);
- index de ligne (df.index()): nombres entiers (numéros des lignes), chaînes de caractères, DatetimeIndex ou PeriodIndex pour les séries temporelles (time series).
C’est l’équivalent d’une matrice NumPy dont chaque colonne (Serie) est de même type (n’importe quel type de données, objets Python, nombres, dates, textes, binaires) et qui peut contenir des valeurs manquantes. C’est aussi l’équivalent des Data Frame de R (il y a aussi moyen de travailler avec des données selon 3 dimensions ou plus avec les Pandas Panels, mais le sujet ne sera pas abordé ici).
Cette manière de représenter les données oblige à changer quelque peu les habitudes de programmation. On travaille sur des colonnes, des lignes ou des cellules au lieu de parcourir l’ensemble des données avec des boucles et/ou des boucles imbriquées. Par exemple, pour modifier toutes les valeurs d'une colonne on utilisera pandas.Series.map(fonction).
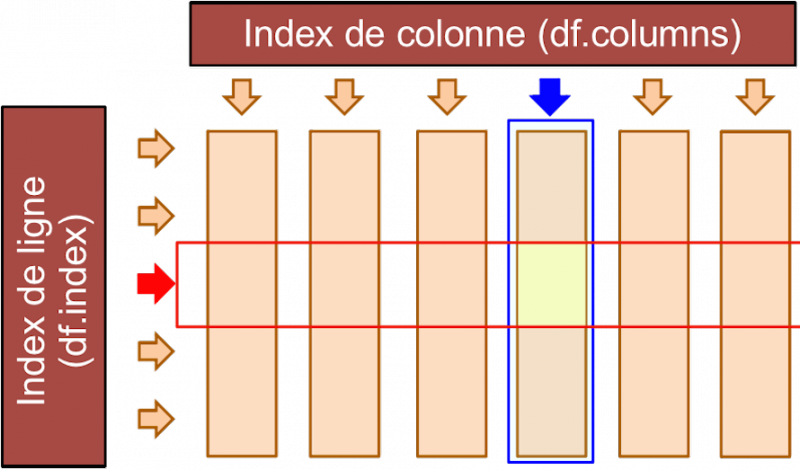
Pandas permet nativement:
- la création et l'exportation de tables de données à partir d'objets Python (listes, dictionnaires, arrays NumPy,..), de fichiers textes (séparateurs, .csv, format fixe, compressés), de fichiers Excel ou LibreOffice, de fichiers HTML, XML, JSON ou à partir de nombreux systèmes de bases de données (Pandas: IO Tools (Text, CSV, HDF5, ...) ;
- la gestion des tables : sélection des lignes, colonnes, gestion des types et formats, transformations, réorganisation, discrétisation de variables quantitatives, traitement des données manquantes, permutation et échantillonnage aléatoire, variables indicatrices, chaînes de caractères...(Pandas: Intro to Data Structure);
- les statistiques élémentaires uni et bivariées, les statistiques par groupe, les détections élémentaires de valeurs atypiques et les graphiques associés...(Pandas: Computational tools):
- les manipulation de tables : concaténations, agrégations, fusions, jointures, tri .(Pandas: Group By: split-apply-combine, Pandas: Merge, join, and concatenate, Pandas: Database-style DataFrame joining/merging, Pandas: Reshaping and Pivot Tables, ...)
Cette librairie n'est pas isolée, car un grand nombre de modules se sont développes autour de sa structure pour offrir des traitements supplémentaires. C'est l'Ecosystème Pandas. Il est de plus, tout à fait possible d'utiliser Pandas avec une multitude d'autres librairies Python. Autant dire que ses possibilités deviennent presque infinies, d'où son succès actuel.
"Essentially, you can think of
pandasas a Numpy "on steroids" with a focus on real-world data. It encapsulates and wraps around much of the low-level functionality ofnumpy,scipyandmatplotlib, exposing it to the end-user in a much friendlier way." (tiré de Brief introduction to the Python stack for scientific computing)
GeoPandas

Figure réalisée avec GeoPandas (Delaunay, Voronoï) en s'inspirant de Origami Panda Print
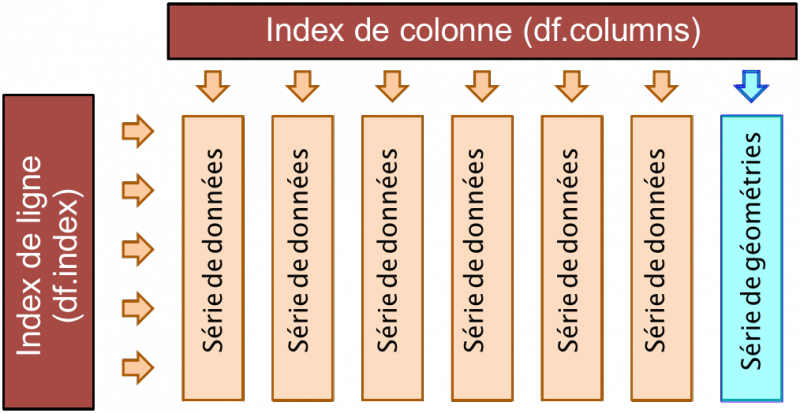
Le monde géospatial ne pouvait pas rester en reste d'où la création de GeoPandas qui est une extension geospatiale de Pandas. Elle rajoute les GeoSeries (géométries, en bleu clair) et les GeoDataFrames ou DataFrames avec une colonne GeoSerie aux structures de Pandas (GeoPandas: Data Structures). Le résultat final est une structure où tous les traitements de Pandas sont possibles sur les colonnes oranges (attributs, Panda Series) et les traitements géomatiques sur la colonne bleu clair (geospatial, Geopandas GeoSerie). En pratique une GeoSerie est constituée de géométries Shapely. Une ligne d'un GeoDataFrame contient donc les attributs et la géométrie d'un élément.
GeoPandas utilise donc Shapely (pour les traitements géométriques), mais aussi Fiona (pour l'importation/exportation des données géospatiales), pyproj (pour le traitement des projections), éventuellement Rtree (facultatif, pour implémenter les index spatiaux) et matplotlib et descartes pour les graphismes. Hormis Rtree, tous ces modules doivent être préalablement installés, Pandas y compris, bien évidemment. Le tout est particulièrement bien adapté aux Jupyter/IPython notebooks (voir Les notebooks IPython comme outil de travail dans le domaine géospatial ou le plaisir de partager, de collaborer et de communiquer) sur le Portail).
Quelques principes
Ouvrir et sauvegarder un fichier shapefile (ou autre) est enfantin et a été vu dans Python à finalité géospatiale: pourquoi débuter avec le module ogr alors qu'il existe des alternatives plus simples et plus didactiques ?
Le fichier shapefile d'origine
Transformation en GeoDataFrame
import geopandas as gpd# Création d'un GeoDataFramegdf = gpd.read_file("test_portail.shp")gdf.head()
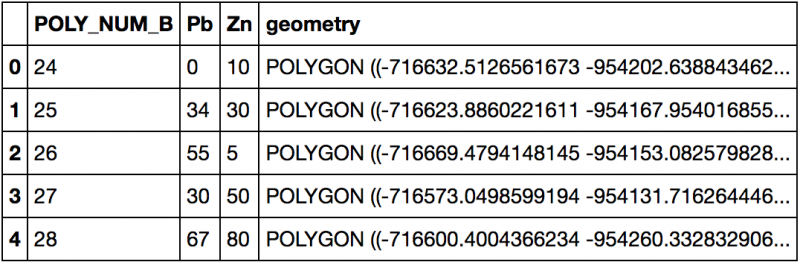
Quelques manipulation avec Pandas
À ce stade il est possible de modifier la table (ajout/suppression d'un champ par exemple), d'appliquer toutes les fonctions de Pandas pour ajouter/manipuler les attributs, de traiter l'ensemble d'une colonne (somme, moyenne, ...) ou de plusieurs colonnes (corrélations, ...)
- Ajout d'un nouveau champ, soit avec une fonction de Pandas soit avec une fonction de GeoPandas (ici):
gdf["surface"] = gdf['geometry'].areagdf.head(2) # 2 premières lignes

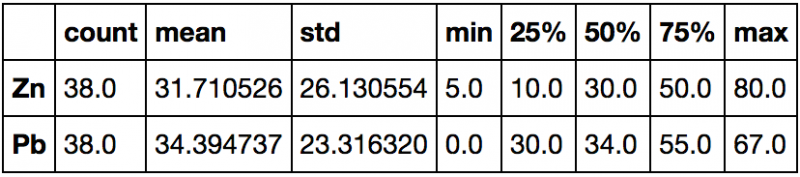
- Quelques statistiques basiques:
gdf[['Zn','Pb']].describe().transpose()
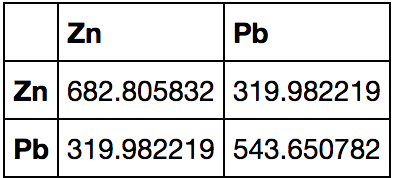
gdf[['Zn','Pb']].cov() # covariance
À tout moment il y a la possibilité de sauver le GeoDataFrame résultant
gdf.to_file("resultat.shp")
Je vous laisse découvrir Pandas pour tous les traitements possibles (une multitude), car ce qui nous intéresse ici ce sont les traitements géomatiques.
Quelques manipulations géométriques avec GeoPandas
Je vais vous montrer ici comment convertir ce GeoDataFrame en 4 fichiers shapefiles tout en gardant les attributs en illustrant les manières de procéder (je repars du fichier original):
- la transformation de polygones en points se fera avec la fonction centroid de GeoPandas;
- la transformation de polygones en lignes se fera avec Shapely et la commande map de GeoPandas et les fonctions lambda puisque la commande native n'existe pas et qu'il est nécessaire d'appliquer la fonction à chaque élément de la GeoSerie;
- la transformation de lignes en points se fera de la même manière, mais le résultat aura évidemment plus de lignes.
Je vais sans doute être un peu long pour certains, mais il faut bien comprendre ici les manipulations géométriques sous peine d’être perdu dans la suite.
- Transformation du GeoDataFrame en fichier shapefile de type point
# copie du GeoDataFrame originalpoints = gdf.copy()points.geometry = points['geometry'].centroid# même crs que l'originalpoints.crs = gdf.crs# sauvetage du fichier shapefilepoints.to_file('centroid_portail.shp')points.head()
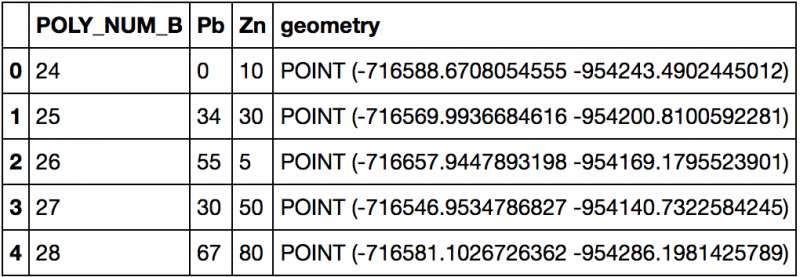
- Transformation du GeoDataFrame en shapefile de type polylignes. Ici il est nécessaire d'utiliser une fonction extérieure puis d'utiliser la fonction map
from shapely.geometry import LineString# la fonction de transformation de polygones en polyligneslinear = gdf.copy()def convert(geom):return LineString(list(geom.exterior.coords))# application de la fonction à toutes les lignes de la colonne geometrylinear.geometry= linear.geometry.map(convert, linear['geometry'])# ou directement avec les fonctions lambdaslinear.geometry= linear.geometry.map(lambda x: LineString(list(x.exterior.coords)))linear.crs = gdf.crslinear.head()
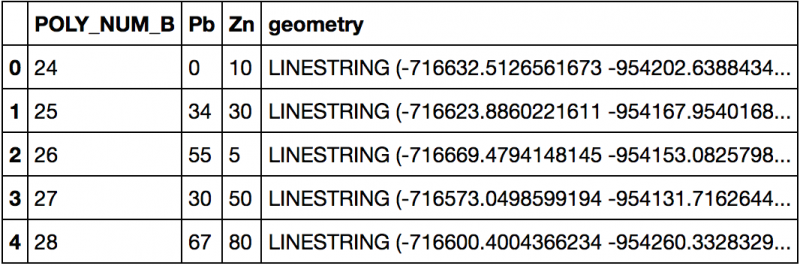
- Extraction des noeuds des polylignes: ici il faut extraire les noeuds des lignes (LineString) de linear et créer un nouveau GeoDataFrame
col = linear.columns.tolist()[0:4]print col[u'POLY_NUM_B', u'Pb', u'Zn', 'geometry']# création d'un nouveau GeoDataFrame avec ces colonnesnoeuds = gpd.GeoDataFrame(columns=col)# extraction des noeuds à partir des lignes présentes dans linear et des valeurs d'attributs et intégration dans le nouveau GeoDataFramefor index, row in linear.iterrows():for j in list(row['geometry'].coords):noeuds = noeuds.append({'POLY_NUM_B': int(row['POLY_NUM_B']), 'Pb':row['Pb'],'Zn':row['Zn'], 'geometry':Point(j) },ignore_index=True)noeuds.crs = {'init' :'epsg:31370'} # autre manière de spécifier les coordonnées
Comme je veux être sûr que mes valeurs soient de type entier, je le spécifie:
noeuds['POLY_NUM_B'] = noeuds['POLY_NUM_B'].astype('int')noeuds['Pb'] = noeuds['Pb'].astype('int')noeuds['Zn'] = noeuds['Zn'].astype('int')# affichage des éléments 8 à 16noeuds[8:16]
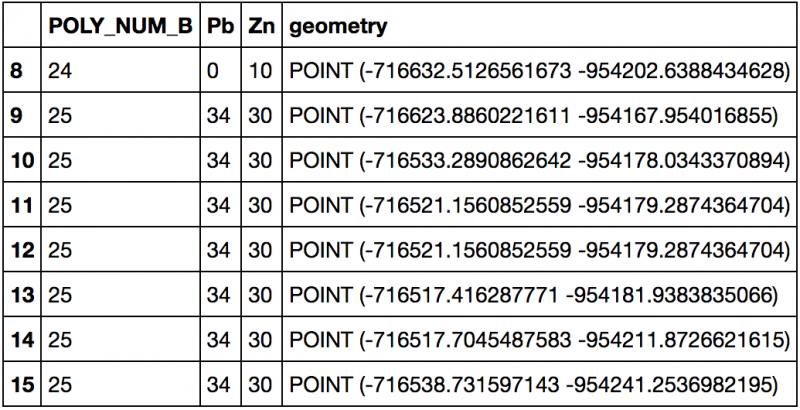
- je crée maintenant un buffer autour de ces points
buffer = df.copy()buffer.geometry = buffer['geometry'].buffer(5)etc.
- Résultat
En pratique
1) Une des plus belles illustrations de la puissance de GeoPandas m'a été apportée suite à une de mes réponses sur GIS Stack Exchange. La question posée était "More Efficient Spatial join in Python without QGIS, ArcGIS, PostGIS, etc". J'ai répondu avec une solution classique de boucles imbriquées en parcourant les 2 fichiers shapefiles (ma réponse) à comparer avec la réponse avec GeoPandas qui illustre les jointures spatiales (GeoPandas: spatial joins)
points = geopandas.GeoDataFrame.from_file('points.shp') # or geojson etcpolys = geopandas.GeoDataFrame.from_file('polys.shp')pointInPoly = gpd.sjoin(points, polys, how='left',op='within')
Et vous obtiendrez un GeoDataFrame avec tous les points de 'points.shp' qui sont dans les polygones de 'polys.shp'.
2) Transformer un fichier csv ou Excel en GeoDataFrame est très facile:
import pandas as pd# transformation du fichier csv en Pandas DataFramepoints = pd.read_csv("strati.csv")#transformation en GeoDataFramefrom shapely.geometry import Pointgeometrie = [Point(xy) for xy in zip(points.x, points.y)] # colonnes du DataFrame résultantspoints = gpd.GeoDataFrame(points,geometry=geometrie)# ou directementpoints = pd.read_csv("strati.csv")points['geometry'] = points.apply(lambda p: Point(p.x, p.y), axis=1)
3) fusionner 2 ou plusieurs shapefiles, quelque soit le nombre et le type de champs, pourvu que le type de géométrie soit le même:
a = gpd.GeoDataFrame.from_file("shape1.shp")b = gpd.GeoDataFrame.from_file("shape2.shp")import pandas as pdresult = pd.concat([a,b],axis=0)result.to_file("merged.shp")
4) un cas pratique auquel j'ai été confronté. J'ai un fichier shapefile reprenant les affleurements géologiques d'une carte (lignes) et un fichier csv avec leurs descriptions et je voudrai extraire les valeurs de schistosité de chacun d'entre eux pour créer un nouveau fichier shapefile de type point:
import geopandas as gpdimport pandas as pdimport reaffl = gpd.GeoDataFrame.from_file("aff.shp")affl.head(2)

Traitement du fichier csv
affleurs = "schisto.csv"# je choisis les colonnes que je veux importeru_cols = ['IDENT','desc']affleurs = pd.read_csv(aff, sep='\t', names=u_cols)regex = re.compile("S1.\d{1,2}\W*\d{1,3}")# je saute la partie du script pour chercher le regex et le résultat estaffleurs.head(2) # les 2 premiers éléments
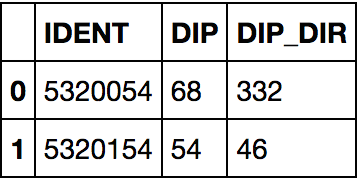
Je joins les 2 DataFrames sur base du champ 'IDENT' et je modifie la géométrie
df2 = gpd.GeoDataFrame( pd.merge(affl, affleurs, on='IDENT'))df2['geometry'] = df2['geometry'].representative_point()df2.head(2)

Résultat:

4) Pour le reste je vous renvoie (le choix n'est pas exhaustif):
- aux exemples de Geopandas (notebooks Jupyter/IPython):
- Prototyping choropleth classification schemes from PySAL for use with GeoPandas
- GeoPandas: Overlays
- GeoPandas: Spatial Joins
- à mes réponses ou à celles d'autres personnes sur GIS Stack Exchange ou Stack Overflow:
- Finding if point exists in shapefile using shapely performance?
- Check if a point falls within a multipolygon with Python
- Merging overlapping features using Geopandas?
- How to convert multiple csv files to shp using python and no arcpy?
- Turn a GeoDataFrame of x,y coordinates into Linestrings using GROUPBY?
- How to check what changed inside the updated shapefile?
- How to create a Feature Collection from a GeoJSON
- Write GeoDataFrame into SQL Database
- à des exemples de combinaisons avec d'autres librairies:
- Mapping in Python with geopandas (notebook Jupyter/IPython)
- Basic Interactive Geospatial Analysis in Python
- Geodata manipulation with GeoPandas: Third in a series on scikit-learn and GeoPandas
- Prepare data for clustering lab (notebook Jupyter/IPython)
- Clustering, spatial clustering, and geodemographics (notebook Jupyter/IPython)
- Programming a seismic program (notebook Jupyter/IPython)
Conclusions
Contrairement à la plupart des tutoriels, je n'ai pas développé ici les fonctionnalités graphiques de la librairie puisque j'utilise un logiciel SIG pour visualiser les résultats. GeoPandas est encore jeune, mais ses possibilités sont déjà énormes, si vous aimez programmer, bien entendu. Dans mon cas, les traitements sont beaucoup plus rapides qu'avec QGIS pour ce que je veux faire (je ne dois pas utiliser PyQGIS, PyGRASS et leurs contraintes pour travailler sur des fichiers shapefiles. Tant que la colonne geometry d'un GeoDataFrame demeure inchangée, il y a moyen de faire ce que l'on veut avec les attributs).
Du fait que la librairie utilise Fiona, elle est sujette aux mêmes restrictions (pas d'accès direct aux bases de données spatiales par exemple), mais il est possible de contourner cet aspect avec d'autres modules plus adéquats. De part sa jeunesse elle est encore sujette à des erreurs non rédhibitoires (voir GeoPandas commits).
Signalons aussi OSMnx, pour le traitement des couches OpenStreetMap avec Pandas et GeoRasters qui se veut l'équivalent de GeoPandas pour les rasters.
Tous les traitements présentés ont été effectués sur Mac OS X, Linux ou Windows avec les versions 0.1.x, 0.2.0 et 0.2.1 de GeoPandas et les versions 0.18.x puis 0.19.0 de Pandas.
 Site officiel :
Using geopandas on Windows
Site officiel :
Pandas DataFrame Notes (PDF)
Site officiel :
Using geopandas on Windows
Site officiel :
Pandas DataFrame Notes (PDF)  Site officiel :
DataFrame et Matrice
Site officiel :
DataFrame et Graphes
Site officiel :
Le pandas c’est bon, mangez en
Site officiel :
Introduction à Pandas
Site officiel :
DataFrame et Matrice
Site officiel :
DataFrame et Graphes
Site officiel :
Le pandas c’est bon, mangez en
Site officiel :
Introduction à Pandas 
licence Creative Commons Paternité-Pas d'Utilisation Commerciale-Pas de Modification 2.0 France
Commentaires
super, comme toujours
Bonjour,
J'ai "dévoré" une bonne partie des tutos que vous avez rédigé, et je n'ai jamais pris le temps de vous remercier. Donc... Un grand merci!
Super tuto
merci beaucoup !
autant on a le choix pour la visualisaion (Folium,D3,Basemap etc ) autant Geopandas semble de plus en plus incontournable pour la manipulation.
ce tuto est de l'or, continuez
Poster un nouveau commentaire